
Często zdarza się, że podczas projektowania aplikacji nie jesteś w stanie przewidzieć jaki model danych będzie najlepszym dla Ciebie. Dopiero w późniejszym etapie wychodzą różne przypadki, które wskazują na użyteczność konkretnego modelu bazy danych. Czasem wygląda to następująco:
– zaczynasz eksperymentować z różnymi modelami danych,
– zespół wybiera jeden z nich,
– pojawia się pierwszy skomplikowany przypadek, ale nadal wierzycie, że wasz wybór jest dobry,
– aplikacja zostaje wgrana na produkcje (zostaje udostępniona dla użytkowników),
– użytkownicy zaczynają ją używać i generują dużo danych,
– zespół dochodzi do wniosku, że aplikacja zaczyna działać coraz wolniej i rozważa pewne modyfikacje,
– zmiany w kodzie nie przynoszą efektów, więc zespół rozważa zmianę bazy danych,
– pojawia się pewien problem: “Co zrobić z istniejącymi danymi i jak przenieść je do nowo wybranej bazy danych?”,
Istnieje spore prawdopodobieństwo, że w Twojej karierze wystąpi powyższy przypadek. Przeważnie migracje danych występują między tymi samymi rodzajami baz danych. Takim przypadkiem może być sytuacja gdy z monolitycznego systemu wydzielamy mikroservice, wtedy migrujemy część bazy danych, z której korzysta wydzielony kod.
Ciekawszym przypadkiem, na jaki można natrafić, jest migracja między różnymi systemami baz danych. W tym poście opiszę migrację z PostgresSQL do Neo4j. Na początku sama myśl o tym, że migracja jest konieczna bylem przerażony, ale po przeczytaniu dokumentacji znacząco zmieniłem swoje zdanie.
Wprowadzenie
Aplikacja z tłumaczeniami
Razem z kolegą zaczęliśmy pracę nad aplikacją, w której użytkownik mógł uczyć się słówek w innych językach. Mając to wymaganie w głowach, zbudowaliśmy elastyczny model bazy danych pozwalający na dodawanie słów i połączeń między nimi bez potrzeby modyfikacji schematu. To wszystko na Postgresie. Dodam, że zaplanowaliśmy możliwość uczenia się więcej niż dwóch języków (na początku było ich 5). W planie mieliśmy połączenie tych wszystkich języków między sobą, aby dodając jedno tłumaczenie, system automatycznie dodawał tłumaczenia z innych języków. Udało się, ale największym problemem było dla nas zrobienie tego poprawnie. Kod stał się bardzo zawiły i każda modyfikacja sprawiała, że czułem się bardzo sfrustrowany.
Połączenia między słowami
Krótko wspomnę o problemie, który popchnął mnie w jednym kierunku – migracja na Neo4j. Załóżmy, że w bazie danych mamy tłumaczenie z języka angielskiego na niemiecki (np. mother -> die Mutter). Teraz chciałbym dodać tłumaczenie z języka polskiego na angielski (matka -> mother). Nasza idea zakładała, że system automatycznie zrozumie, że matka po polsku to die Mutter po niemiecku. Stworzyliśmy specjalny mechanizm, który łączył za nas te dane i nawet działał. Problem zaczął się pojawiać gdy dodaliśmy dwa dodatkowe języki oraz synonimy w każdym z nich. Aplikacja działała wolniej, a w bazie danych, tworzyły się tysiące relacji.
Duża złożoność przy pobieraniu danych
Mając tak skomplikowany model danych, pobieranie informacji z bazy jest dość złożoną operacją. Nasze zapytanie o wszystkie tłumaczenia z jednego języka na drugie wymagało złączenia przynajmniej trzech tabel, z czego niektóre musiały się łączyć same ze sobą. Praktycznie zawsze tak duże zapytania z dużą ilością JOINów sprawiają późniejsze problemy.
Migracja na Neo4j – Lekarstwo na nasze problemy
Kiedy już zacząłem gubić się w swoim własnym kodzie, zaczęliśmy myśleć o kompletnie innej bazie danych. Słowo połączenia, które często się pojawiało, mylnie kierowało nas w kierunku relacyjnej bazy danych. Znacznie szybszym, wygodniejszym i stworzonym do tego typu problemów rozwiązaniem jest Neo4j. W normalnym przypadku ta baza nie jest darmowa do komercyjnego użytku, ale jest to narzędzie darmowe dla startupów oraz do nauki. Mając wyjaśnioną tę sytuację, zabraliśmy się za migrację.
Relacyjna baza danych

Powyższy schemat prezentuje część naszego modelu bazy danych (tak wiem, schemat nie jest zgodny z żadnym standardem – to rysunek poglądowy). Faktycznie baza jest dużo większa, ale na potrzeby tego posta wystarczy to, co jest na obrazku.
Phrase w tym modelu oznaczał tabelę, w której przechowujemy wszystkie słowa oraz proste zdania w różnych językach. PhraseAssociation jest miejscem, gdzie zapisujemy połączenia między wyrazami. Każde połączenie ma jeden z trzech typów TRANSLATION, SYNONYM lub ANTONYM. Tabela Sentence jest kontenerem na zdania, służące jako przykładowe użycia poszczególnych słów. PhraseSentence jest tabelą łączącą słowa z ich przykładowym użyciem.
W tym momencie wydaje się, że jest to prosty model. Problem pojawia się w momencie gdy do bazy danych dodajemy kolejne wyrazy w różnych językach, przykłady ich użycia i łączymy to wszystko ze sobą. W przypadku pięciu różnych języków aplikacja do jednego dodanego słowa tworzy przynajmniej 5 dodatkowych połączeń. Zrozumienie tych danych po pewnym czasie było nie lada wyzwaniem.
Mając taki model danych, pobieranie przykładowych tłumaczeń (w tym przypadku z polskiego na niemiecki) wymagało napisania kilku JOINów.
SELECT p1.text as TEXT_FROM,
l1.lang as LANG_FROM,
p2.id AS ID_TO,
l2.lang as LANG_TO
FROM zettelchen_phrase p1
JOIN zettelchen_language l1 ON p1.lang_id = l1.id
JOIN zettelchen_phrase_phrase_association zppa1 on p1.id = zppa1.phrase_id
JOIN zettelchen_phrase_association zpa ON zppa1.phrase_association_id = zpa.id
JOIN zettelchen_association_type zat ON zat.id = zpa.association_type_id
JOIN zettelchen_phrase_phrase_association zppa2 ON zppa2.phrase_association_id = zpa.id
JOIN zettelchen_phrase p2 ON zppa2.phrase_id = p2.id
JOIN zettelchen_language l2 ON p2.lang_id = l2.id
WHERE p1.id <> p2.id
AND zat.name = 'TRANSLATION'
AND (p1.text = '') IS NOT TRUE
AND (p2.text = '') IS NOT TRUE
AND (l1.lang = 'pl')
AND (l2.lang = 'de')Łączymy tylko 5 tabel, ale przez złożoność aplikacji zapytanie wygląda na dużo większe.
Model grafowy
Sprawdźmy teraz jak wygląda nasz model danych z użyciem grafu.
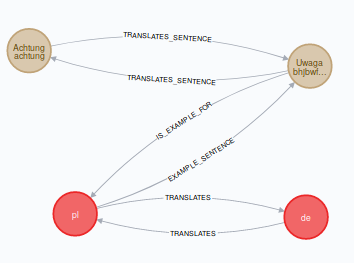
Nasz model bazy danych wygląda następująco. Mamy tylko węzły i 4 typy relacji między nimi. Przyznasz, że ten diagram wygląda dużo bardziej zrozumiale niż ten relacyjny? Gdy chcemy pobrać dokładnie te same tłumaczenia co wczesniej, wystarczy, że użyjemy poniższego zapytania.
MATCH (p:Phrase {lang: 'pl'})-[:TRANSLATES]->(p2:Phrase {lang: 'de'})
RETURN p.text, p.lang, p2.text, p2.langTo wszystko, czego potrzebujemy, aby pobrać tłumaczenia! Zabierzmy się zatem za migrację!
Zapisz się na newsletter, aby otrzymywać informacje o nowych artykułach oraz inne dodatki.
Migracja danych krok po kroku
Zarówno nasza aplikacja jak i baza danych jest uruchomiona na dockerze, dlatego niektóre kroki zawierają komendy z dockera.
1. Przygotowanie zapytania SQL do wyciągnięcia danych z Postgresa i export ich do pliku CSV.
COPY (
SELECT p1.id AS ID_FROM,
p1.text as TEXT_FROM,
l1.lang as LANG_FROM,
p2.id AS ID_TO,
p2.text as TEXT_TO,
l2.lang as LANG_TO
FROM zettelchen_phrase p1
JOIN zettelchen_language l1 ON p1.lang_id = l1.id
JOIN zettelchen_phrase_phrase_association zppa1 on p1.id = zppa1.phrase_id
JOIN zettelchen_phrase_association zpa ON zppa1.phrase_association_id = zpa.id
JOIN zettelchen_association_type zat ON zat.id = zpa.association_type_id
JOIN zettelchen_phrase_phrase_association zppa2 ON zppa2.phrase_association_id = zpa.id
JOIN zettelchen_phrase p2 ON zppa2.phrase_id = p2.id
JOIN zettelchen_language l2 ON p2.lang_id = l2.id
WHERE p1.id <> p2.id
AND zat.name = 'TRANSLATION'
AND (p1.text = '') IS NOT TRUE
AND (p2.text = '') IS NOT TRUE
) TO '/tmp/translations.csv' WITH CSV header;W powyższym zapytaniu ważne są użyte aliasy. Posłużą one jako nagłówki w pliku CSV.
Trzeba pamiętać, że gdy uruchomimy to zapytanie do dockerze, plik zostanie zapisany w kontenerze w podanej lokalizacji.
2. Przygotuj zapytanie CYPHER przy użyciu narzędzia LOAD CSV do importowania danych
USING PERIODIC COMMIT
LOAD CSV WITH HEADERS FROM 'file:/translations.csv' AS row
MERGE (from:Phrase {
externalId: row.id_from
})
ON CREATE SET
from.uuid = randomUUID(),
from.text = row.text_from,
from.lang = row.lang_from
MERGE (to:Phrase {
externalId: row.id_to
})
ON CREATE SET
to.uuid = randomUUID(),
to.text = row.text_to,
to.lang = row.lang_to
MERGE (from)-[r:TRANSLATES {
code: row.lang_from + '-' + row.lang_to
}]->(to);W powyższym skrypcie czytamy wszystkie wiersze z pliku CSV linia po linii, tworząc nowe węzły i połączenia między nimi. W tym miejscu, tworząc właściwości wierszy i relacji, używamy wcześniej przygotowanych aliasów. Plik CSV powinien być umieszczony w katalogu import. Nazwa jest dowolna, ja wybrałem import.cypher.
3. Uruchom skrypt z pierwszego kroku
Aby móc wyeksportować dane, możemy użyć narzędzia psql. Poniższa komenda ładuje podany plik i uruchamia go. Możemy do wywołać z zewnątrz kontenera dockera, ale plik i tak zostanie odłożony wewnątrz niego.
psql -h $POSTGRES_HOST -p $POSTGRES_PORT -U $POSTGRES_USER -d $POSTGRES_DB < export_csv.sql4. Pobierz wyeksportowany plik z dockera
docker cp $POSTGRES_CONTAINER_ID:/tmp/translations.csv translations.csvPodpowiedź: Jeśli chcesz dowiedzieć się, jaki jest Twój POSTGRES_CONTAINER_ID użyj poniższej komendy.
docker ps -aqf "name=$POSTGRES_CONTAINER_NAME"5. Przenieś plik CSV do katalogu import w kontenerze neo4j
docker cp translations.csv $NEO4J_CONTAINER_ID:/import/translations.csv6. Przenieś plik ze skryptem z kroku 2 do kontenera neo4j ale do katalogu /tmp
docker cp import_csv.cypher $NEO4J_CONTAINER_ID:/tmp/import_csv.cypher7. Użyj cypher-shell do uruchomienia przygotowanego skryptu – właściwa migracja
Przygotuj skrypt shelowy i przenieś go w to samo miejsce co skrypt z kroku 2.
USERNAME=$1
PASSWORD=$2
cat /tmp/import_csv.cypher | /var/lib/neo4j/bin/cypher-shell -u $USERNAME -p $PASSWORDTeraz uruchom skrypt na dockerze, korzystając z opcji exec.
docker exec $NEO4J_CONTAINER_NAME /tmp/$YOUR_SHELL_SCRIPT.sh $USERNAME $PASSWORDOperacja powinna się zakończyć z informacją o sukcesie. W przeciwnym przypadku otrzymasz klarowną informację, co poszło nie tak. Aby zobaczyć więcej szczegółów odnośnie błędów, wystarczy dodać flagę -debug -format verbose do cypher-shell.
8. Usuń tymczasowe pliki
Na koniec warto posprzątać po sobie i usunąć niepotrzebne pliki.
if [ -f translations.csv ] ; then
rm translations.csv
fiPodsumowanie
Jak widzisz, migracja danych jest w zasadzie kwestią przygotowania odpowiednich skryptów do wyciągnięcia danych z jednej bazy i wrzucenia na drugą. Dzięki narzędziu LOAD CSV przenoszenie danych jest bardzo proste. Jak już wspominałem w poprzednim poście, Neo4j pozwala na reprezentację prawdziwych relacji między danymi w bardzo prosty sposób. W pewnych przypadkach baza grafowa sprawdza się świetnie w porównaniu do relacyjnej bazy danych. W naszym przypadku migracja okazała się krokiem w dobrym kierunku. Teraz kod aplikacji jest czystszy i łatwiejszy w utrzymaniu. Dzięki algorytmom grafowym, szybkość pobierania danych znacznie się zwiększyła.
Uważam, że podejście grafowe jest bardzo użytecznie i przyjazne, dlatego rekomenduję każdemu przeczytanie jeszcze raz wymagań waszego systemu, ponieważ może i w waszym przypadku Neo4j będzie użyteczne.
Dziękuję za przeczytanie i zapraszam do dyskusji oraz bezpośredniego kontaktu.
Post napisany na podstawie posta z mojego innego bloga oraz własnych doświadczeń.