Co to jest Sharding?
Sharding jest wzorcem architektonicznym bazy danych związanym z partycjonowaniem horyzontalnym. Praktyka ta polega na rozdystrybuowaniu wierszy w tabeli na różne tabele zwane partycjami. Każda partycja ma ten sam schemat, te same kolumny, ale kompletnie różne wiersze. Dane znajdujące się w jednej partycji są unikalne i niezależne od danych z pozostałych partycji. Każda partycja nazywana jest Shardem, co w tłumaczeniu na polski oznacza odłamek. Poniższy opisuje sposób zarządzania takimi odłamkami bazy danych.
Sharding jest dobrym przykładem implementacji Shared Nothing Architecture.
Różnice między skalowaniem wertykalnym a horyzontalnym
W powyższym akapicie wspominałem o partycjonowaniu, a teraz piszę o skalowaniu. To nie jest to samo. O partycjonowaniu napiszę niżej. Pojęcia horyzontalny i wertykalny bardzo dobrze opisują to, co zamierzamy wdrożyć. Poniższe definicje na pewno pomogą w zrozumieniu zagadnienia.
Skalowanie wertykalne (scale-up) to podejście, w którym próbujemy zwiększać wydajność poprzez zwiększanie możliwości pojedynczej maszyny. Może to być zwiększanie mocy procesora, dodanie większej ilości pamięci lub inne tego typu zabiegi.
Mówiąc o skalowaniu horyzontalnym (scale-out) mamy na myśli dodawanie większej ilości równoległych maszyn czy budowanie klastra. Na każdej maszynie będzie uruchomiony takie samo oprogramowanie. W tym przypadku potrzebujemy dodatkowego mechanizmu, jakim jest load balancer, który zapewni, że każde żądanie trafi w odpowiednie miejsce.
Partycjonowanie wertykalne vs. horyzontalne
Mówiąc o partycjonowaniu mamy na myśli dane, a dokładniej sposób ich ułożenie w sensowny sposób. Z partycjonowaniem na pewno mieliście do czynienia w przypadku podziału dysków w systemie operacyjnym na mniejsze dyski.
Partycjonowanie wertykalne w bazach danych polega na tworzeniu tabel z mniejszą liczbą kolumn i używaniu innych tabel do zapisywania pozostałych danych. Ogólnie takie partycjonowanie polega na rozdzielaniu danych, które mógłby znajdować się w jednej tabeli na kilka innych. Dobrym motywem do wydzielenia może być większa częstotliwość korzystania (odczyt lub zapis) z niektórych danych. Dla przykładu możemy mieć tabelę z imionami i nazwiskami osób (częste wyszukiwania po tych danych) oraz drugą tabelę z ich numerami telefonów, adresem oraz innymi danymi.
Partycjonowanie horyzontalne polega na zapisywaniu różnych wierszy w różnych tabelach tego samego typu. Za przykład posłuży baza danych firm. Schemat bazy danych będzie wyglądał tak samo dla każdej instancji. Różnica będzie w podziale danych. W przypadku firm możemy przyjąć kryterium liczby pracowników np. mniej niż 100 pracowników, 100 – 10000 pracowników oraz powyżej 10000. Na tej podstawie możemy stworzyć 3 bazy danych z takim samym schematem, ale różnymi danymi. Takie partycjonowanie może być przydatne w systemach multitenant, gdzie dodatkową zaletą shardingu będzie brak konieczności tworzenia dodatkowych zabezpieczeń, aby uniknąć wyciekom danych między tenantami.
Zalety Shardingu
- Mechanizm shardingu pozwala nam na skalowanie horyzontalne,
- Zwiększenie czasu odpowiedzi zapytań – dzięki podziałowi danych zapytania nie muszą przeglądać wszystkich wierszy w tabeli,
- Zmniejszenie ryzyka kompletnej awarii systemu – nawet w przypadku gdy któraś z maszyn przestanie działać, pozostałe nadal będą uruchomione. Może nie jest to idealne rozwiązanie, ale lepiej gdy aplikacja działa przynajmniej dla części użytkowników, niż miałaby wcale nie działać.
- Może redukować koszty. Dużo implementacji tej architektury opiera się o niskokosztowe darmowe bazy danych, które nie wymagają drogiego hardware, aby działać wydajnie.
Wady Shardingu
- Zaprojektowanie systemu w taki sposób, aby wykorzystać mechanizm shardingu, jest skomplikowane. Nieprawidłowa implementacja może spowodować niespójność, a nawet utratę danych
- Bazy danych mogą okazać się nieprawidłowo zbalansowane. To oznacza, że niektóre shardy mogą być bardziej eksploatowane niż inne. Mamy wtedy do czynienia z hotspotem.
- Raz podzielona baza danych może być trudna do przywrócenia gdy jednak zdecydujemy się korzystać z jednej instancji.
- Nie każda baza danych natywnie wspiera sharding.
Co to hotspot?
Hotspot to shard, który jest używany dużo częściej niż inne. Załóżmy, że w bazie danych mamy tabelę użytkowników i zdecydowaliśmy, że podział będzie odbywał się na podstawie nazwisk. Tak więc mamy dwie grupy: A-M oraz N-Z. Jakimś dziwnym sposobem 3/4 użytkowników ma nazwisko zaczynające się od litery z drugiej grupy. W tym przypadku hotspotem będzie ta instancja, która obsługuję użytkowników N-Z i nie jest to pożądane zjawisko.
Zapisz się na newsletter, aby otrzymywać informacje o nowych artykułach oraz inne dodatki.
Architektura
Key Based Sharding
Inna nazwa dla tego podejścia to hash based sharding. Polega ono na użyciu jakiegoś klucza (ID, IP, kod pocztowy, kod państwa itp) z nowo generowanej wartości i użycia go jako wsad do funkcji generującej hash. Na podstawie tej wygenerowanej wartości podejmowana jest decyzja, który shard ma obsługiwać te dane.
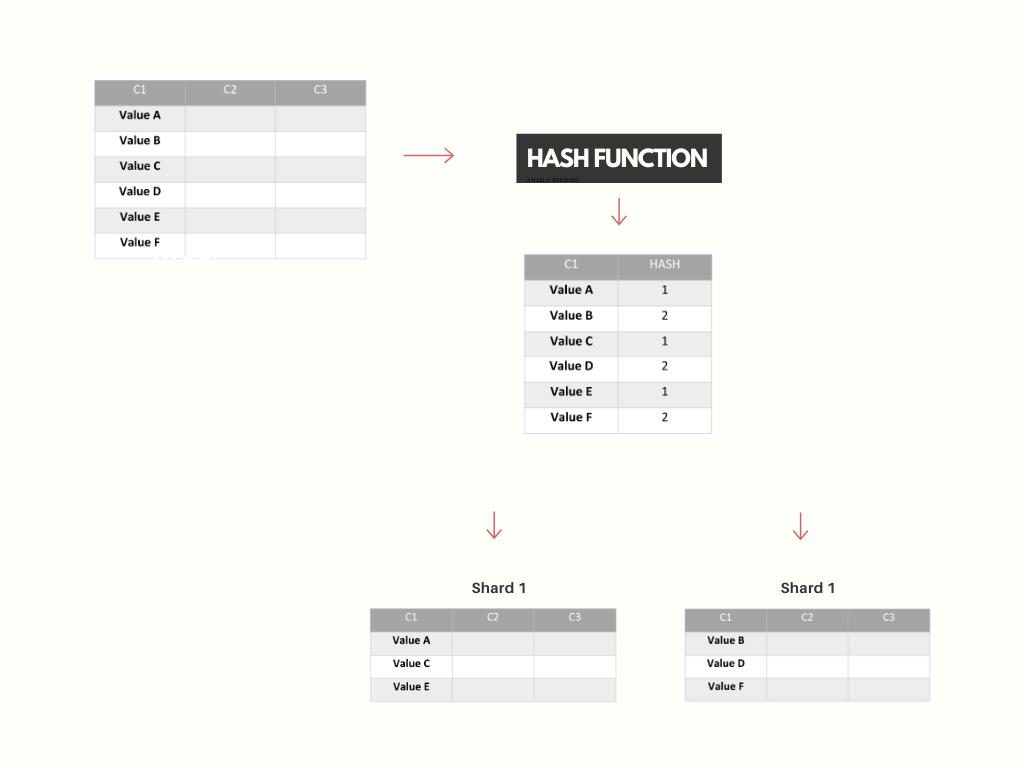
Próby dodania nowej maszyny mogą być nieco skomplikowane. W takim przypadku potrzebujemy wygenerować nowy klucz dla nowego sharda. Może się również okazać, że będziemy musieli przegenerować część lub nawet wszystkie klucze dla wartości z pozostałych shardów oraz odpowiednio te wartości przemigrować.
Zaletą tego podejścia jest równomierne rozłożenie elementów między maszynami, aby uniknąć hotspotów.
Range Based Sharding
To podejście cechuje się podziałem bazującym na pewnych zakresach. Może to być np. cena czy rozmiar.

Zaletą tego podejścia jest łatwość implementacji. Jeśli z góry wiemy, że mamy ustalenie gdzie trafiają które dane to wystarczy napisać odpowiedni kod, który sprawdzi ten warunek.
Wadą jest możliwość wystąpienia hotspotów. Nie jesteśmy w stanie zapewnić, że nasze zakresy będą równomiernie rozłożone między shardami.
Directory Based Sharding
Aby zaimplementować tę architekturę, najpierw trzeba utworzyć specjalną tabelę, która będzie zawierać klucze. Klucze w tabeli mówią nam, który shard zawiera dane, które nas interesują.
To podejście jest podobne do range based sharding. Różnica jest taka, że zamiast nie musimy ustalać za każdym razem, gdzie trafią dane, tabela z kluczami po prostu nam to “powie”.
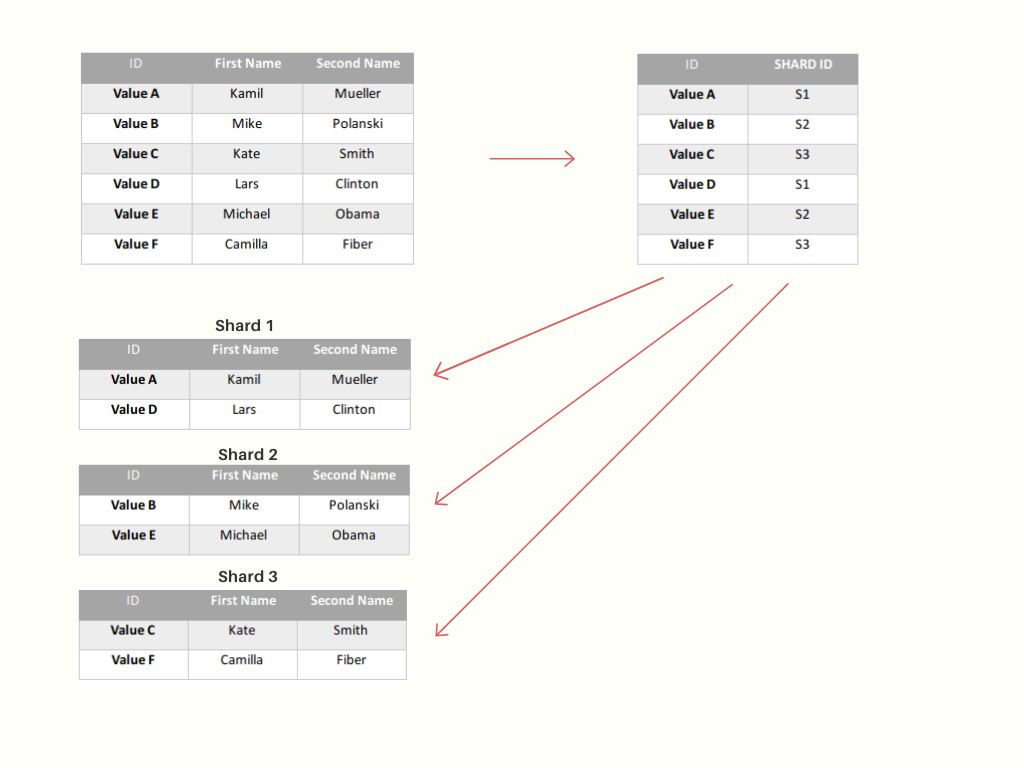
Dużą zaletą tej architektury jest jej elastyczność. W przeciwieństwie do dwóch wyżej opisanych podejść możemy zastosować dowolny algorytm rozmieszczenia danych. Zwiększenie ilości maszyn również będzie łatwiejsze.
Minusem jest fakt, że przy każdym żądaniu musimy wykonać zapytanie do dodatkowej tabeli. Jeśli okaże się, że została ona nieoptymalnie zbudowana, to przy większych ilościach danych może spowalniać działanie.
Co zoptymalizować, zanim zdecydujesz się na sharding?
Zanim zdecydujesz się wdrożyć sharding w swoim systemie, rozważ poniższe rozwiązania.
- Zdalna baza danych – jeśli Twój system bazy danych jest zainstalowany na tym samym serwerze co aplikacja, możesz zwiększyć wydajność przez odciążenie maszyny i przeniesienie bazy na zupełnie inną. To nie jest skomplikowana operacja, ale powinna zwiększyć wydajność.
- Implementacja pamięci podręcznej – implementacja cacheingu może być dobrym pomysłem gdy problemem w Twoim systemie są wolne odczyty.
- Stworzenie repliki – chodzi po prostu o skopiowanie bazy danych tak, aby równocześnie działało więcej instancji. W tym przypadku mamy różne podejścia: master-slave, jedna instancja do zapisu a druga do odczytu itp.
- Skalowanie wertykalne – być może dołożenie większej ilości zasobów sprzętowych do maszyny może spowodować zwiększenie wydajności Twojego systemu.
Podsumowanie
Sharding może wprowadzać większą złożoność do systemu oraz tworzyć potencjalne miejsca wytwarzania się błędów. Należy pamiętać, że sharding nie jest natywnie wspierany w każdym systemie baz danych. Mimo to jest to dobry sposób na zwiększenie wydajności.
Warto wspomnieć o architekturze mikroserwisów. Moim zdaniem, zanim zdecydujemy się na zbudowanie architektury mikrousług, warto zastanowić się, czy sharding nie rozwiąże problemów, z którymi będziemy się zderzać.
P.S. Być może zastanawiasz się, czemu na obrazku wyróżniającym dodałem jakiś budynek. Ta wieża wygląda jak odłamek czegoś większego i nazywa się The Shard.
Dziękuję za przeczytanie mojego artykułu. Zapraszam do poczytania innych wpisów oraz do kontaktu bezpośredniego lub na grupie na facebooku.