Mikroserwisy w ostatnich kilku latach są postrzegane zarówno przez developerów, jak i organizacje jako bardzo sexy podejście do tworzenia aplikacji. Dlaczego tak się dzieje? Mikrousługi są lekkie, stworzone przeważnie w nowoczesnych technologiach, szybkie oraz łatwe w utrzymaniu. Ale co stoi z drugiej strony? Czy są ciemne strony tego podejścia? Książka o ekonomii „Co widać, a czego nie widać”, Frederika Bastiata, uświadomiła mi, że w IT również trzeba zaglądać w te zacienione miejsca, aby podejmować świadome decyzje.
Architektura mikroserwisowa bazuje na koncepcji wydzielania małych niezależnych części kodu z większej aplikacji. W systemach monolitycznych często takie wydzielenie kodu sprowadzane było do stworzenia nowego pakietu lub modułu w aplikacji. Taki moduł finalnie uruchamiany był razem z innymi modułami na serwerze aplikacyjnym oraz traktowany jak jedna aplikacja. Mikroserwisy, w przeciwieństwie do tego podejścia, uruchamiane są niezależnie. Każdy moduł aplikacji uruchomiony jest jako osobna aplikacja, często z własną bazą danych, na własnym serwerze. Taka architektura dostarcza nam ogromną ilość zalet, ale może również stać się dla naszego projektu ogromnym obciążeniem. Jaka zatem jest odpowiedź na pytanie zadane w tytule? Otóż… to zależy. W tym tekście opiszę, z czym wiąże się tworzenie aplikacji w architekturze mikroserwisowej.
Architektura mikroserwisowa

Gdy chcemy stworzyć aplikację w takiej architekturze, będziemy potrzebować kilku dodatkowych narzędzi. To one uczynią naszą infrastrukturę otwartą na skalowanie.
- Na początek potrzebujemy service discovery. Jest to wzorzec, który mówi, o potrzebie posiadania jednego miejsca, w którym każda mikroaplikacja będzie mogła się zarejestrować, aby inne aplikacje wiedziały, pod jakim adresem się znajduje. W rozwiązaniu tego zagadnienia pomogą nam narzędzia takie jak Kubernetes, Consul, Eureka lub inne dedykowane API dostępne w rozwiązaniach chmurowych.
- Aby móc wygodnie zarządzać konfiguracją poszczególnych usług, możemy wdrożyć config serwer. Frameworki takie jak Spring wspierają ten mechanizm. Wystarczy stworzyć nową usługę i przy pomocy odpowiedniego pliku konfiguracyjnego sprawić, że każdy mikroserwis będzie pobierał swoje konfiguracje z jednego miejsca. Pliki konfiguracyjne mogą być przechowywane jako fizyczne pliki na serwerze lub możemy skorzystać z systemu kontroli wersji GIT.
- API gateway to kolejny element naszej mikrousługowej układanki. Aplikację budujemy po to, aby ktoś mógł z się z nią skomunikować. Aby to zrobić, dobrą praktyką jest stworzenie jednego punktu wejścia do systemu, który przekieruje ruch w odpowiednie miejsce. API gateway zatem będzie pełnił nie tylko rolę proxy, ale może się również dobrze sprawdzić jako load-balancer.
- W większości przypadków będziemy potrzebować systemu, który odpowiada za uwierzytelnienie ruchu przechodzącego przez nasz system.
- Dodatkowe sprawy, o które trzeba zadbać w takiej architekturze to: odpowiednie zunifikowane logowanie błędów, śledzenie wiadomości przepływających przez system oraz monitoring aplikacji.

Jak widać, zanim zaczniemy prawdziwy happy-coding aplikacji, musimy sporo nagimnastykować się z konfiguracją infrastruktury. Dodatkowo, aby wdrożyć taki system na serwerze i móc go łatwo utrzymywać, potrzebujemy narzędzia do orkiestracji takiego jak np. Kubernetes, którego również trzeba dostosować do naszych potrzeb.
Zalety
- Możliwość wdrażania części aplikacji. Architektura mikroserwisowa, dzięki posiadaniu niezależnie działających usług, pozwala na wdrażanie części funkcjonalności bez potrzeby zatrzymywania systemu. Dzięki temu unikamy przestojów aplikacji. W najgorszym przypadku tylko niektóre funkcje systemu przestaną na chwilę działać. Dodatkowo downtime systemu będzie niższy niż w przypadku monolitów, ponieważ nie uruchamiamy na raz całego kodu aplikacji, a jedynie małą jego część.
- Możliwość zwiększenia wydajności. Oprócz tego, że każdą usługę możemy uruchomić na osobnych maszynach, co już jest dużym usprawnieniem, mamy możliwość skalowania części aplikacji. Gdy któryś z serwerów ma dużo większe obciążenie niż pozostałe, możemy tę samą część uruchomić więcej niż jeden raz. Równomierne obciążenie serwerów zapewni wdrożony load-balancer.
- Łatwość zrozumienia. Dzięki zwiększonej granulacji w systemie wdrożenie nowych programistów do pracy z mikroserwisami jest dużo prostsze niż w przypadku monolitu.
- Większa izolacja błędów. Błąd w jednym mikroserwisie przeważnie nie wpływa na działanie pozostałych serwisów.
- Możliwość zastosowania różnych technologii. Zespoły piszące aplikację mogą tworzyć każdą mikrousługę w innym języku. Ważne jest, aby wszystkie mikroserwisy komunikowały się ze sobą w ten sam sposób.
Wady
- Mikroserwisy wymagają dokładnego przemyślenia i starannego zaprojektowania. Podczas projektowania należy dobrze przemyśleć, jak będzie odbywać się komunikacja w systemie. Ważne, aby unikać sytuacji, gdy funkcjonalność wymagająca transakcji wykonuje się sekwencyjnie w kilku serwisach. Nie jest to proste zadanie. Gdy okaże się, że musimy zbudować taki mechanizm, trzeba dobudować dodatkowe mechanizmy takie jak Two-Phase-Commit lub implementacja wzorca Saga. To dodatkowo komplikuje implementacje.
- Więcej usług oznacza więcej zasobów potrzebnych, aby uruchomić aplikację, a co za tym idzie, większe koszta.
- Bardziej skomplikowana architektura w porównaniu do monolitu. Obecność wymienionych wcześniej dodatkowych narzędzi oraz mechanizmów czyni architekturę mikroserwisów bardziej skomplikowaną.
- Autoryzacja i uwierzytelnienie w rozproszonych systemach. To zagadnienie jest całkiem proste, dopóki nasz kod i wszystkie żądania mamy zamknięte w jednej fizycznej aplikacji. W przypadku systemów rozproszonych musimy zadbać o dużo mocniejsze zabezpieczenia, ponieważ usługi będą przesyłały żądania między sobą. Dodatkowo każda usługa musi „wiedzieć”, kto wykonuje zapytanie i, czy w ogóle może je wykonać.
- Utrudnione śledzenie błędów. Jako że każdy mikroserwis generuje swój zestaw logów, to w przypadku problemów trzeba przejrzeć więcej plików i porównać z logami z innych serwisów. Aby ten proces ułatwić, stosujemy tracing, ale nadal proces przeglądania logów bywa mozolny.
- Globalne testowanie end-to-end jest trudne. W przypadku monolitu po prostu uruchamiamy aplikację i uruchamiamy testy. W przypadku mikroserwisów wymagane jest odpowiednie uruchomienie wielu mniejszych aplikacji, co może sprawiać problemy z ich orkiestracją.
- Cost per line przy małym systemie jest duży. Na początku trzeba dużo rzeczy skonfigurować i napisać sporo kodu boilerplate, zanim wystartujemy z developmentem. W monolicie koszt linii kodu jest mały na początku, w miarę rozrastania się systemu koszt się zwiększą, linie kosztów przecinają się bardzo daleko.
- Pojawiają się problemy typu shared libraries vs. copy-paste. Z jednej strony zasada DRY (Don’t repeat yourself) mówi o wydzielaniu części wspólnych, lecz doświadczenia programistów często mówią o unikaniu współdzielonych bibliotek w mikrousługach na rzecz starego dobrego copy-paste.
Zapisz się na newsletter, aby otrzymywać informacje o nowych artykułach oraz inne dodatki.
Jeśli nie mikroserwisy, to co?

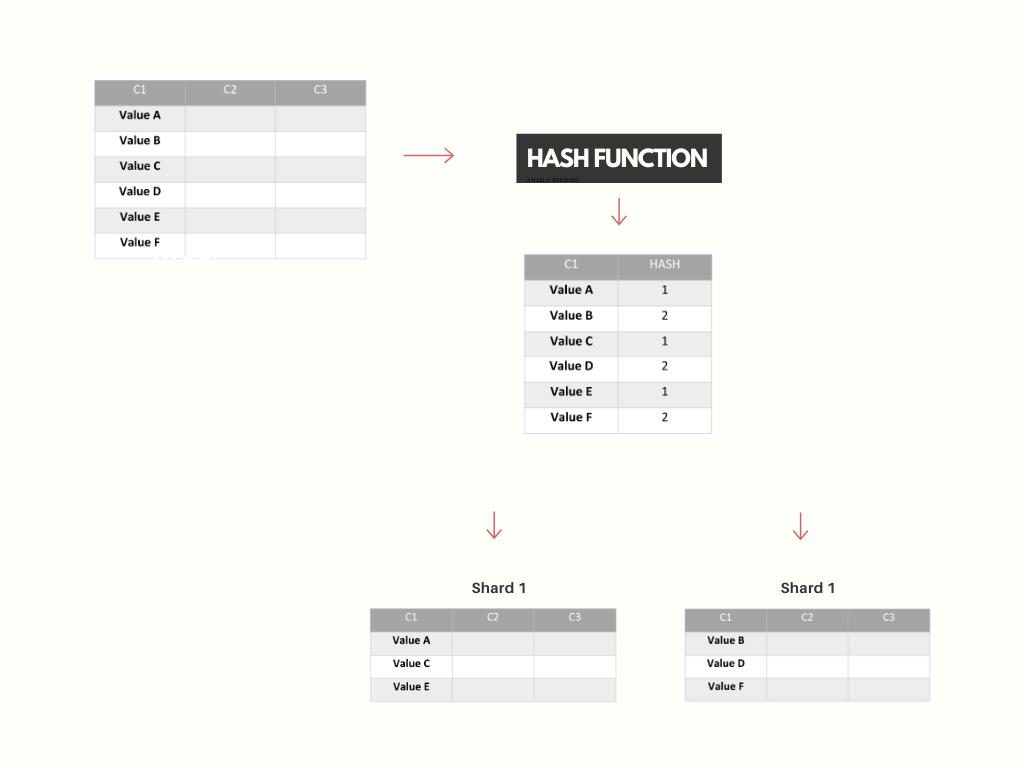
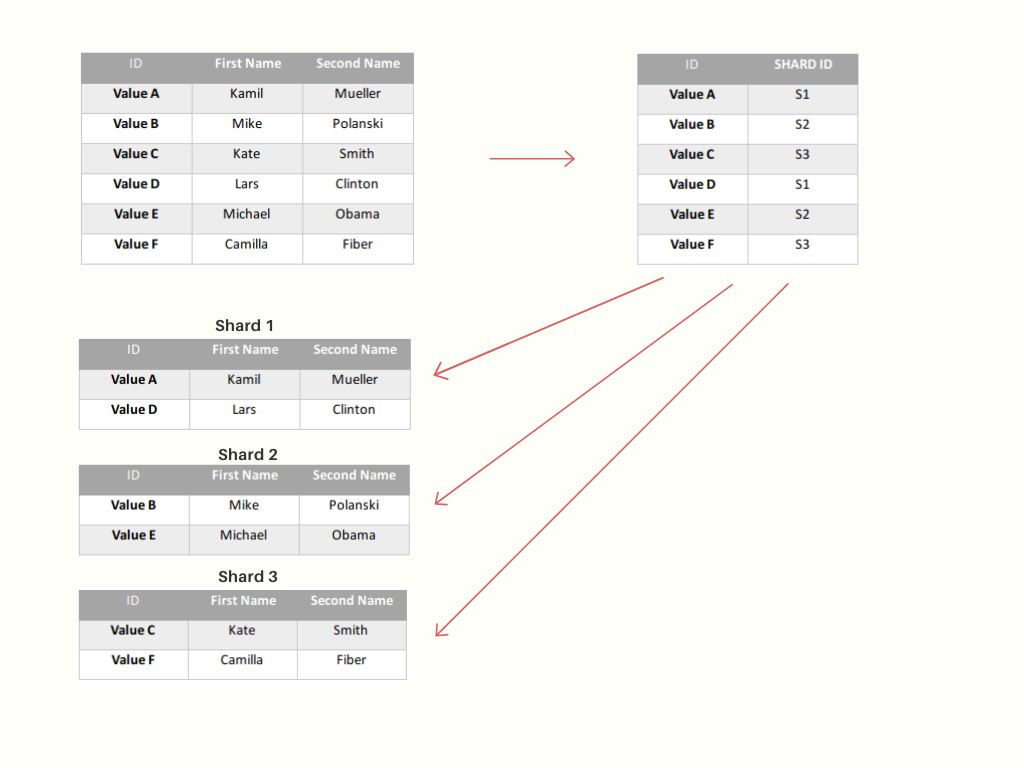
- Sharding bazy danych. W przypadku gdy system staje się mniej wydajny i szybkość zapisu w dużej mierze jest podyktowana szybkością operacji na bazie danych, to być może wystarczy skorzystać ze skalowania horyzontalnego Twojego źródła danych.
- Skupienie się na wydajnych algorytmach – uświadamianie zespołów developerskich na temat złożoności obliczeniowej. W projektach IT często bywa tak, że odpowiedzialność za jakość jest nieco rozmyta. Programiści nie czują się w 100% właścicielami swojego kodu i po prostu budują rozwiązania wystarczające, nie skupiając się na optymalizacji algorytmów. Ciągłe uświadamianie członków zespołu oraz budzenie w nich poczucia odpowiedzialności za napisany kod może przyczynić się do znacznego zwiększenia nie tylko jakości kodu, ale i wydajności.
- Podejście hybrydowe. Być może zamiast budowania całej aplikacji w architekturze mikroserwisowej wystarczy wydzielić z monolitu tylko niektóre kawałki aplikacji, które wymagają szybszego działania.
Podsumowanie
Jak widać, mikroserwisy mogą wnieść wiele dobrego, ale również mogą stać się sporym obciążeniem. Jeśli nie masz zamiaru przetwarzać ogromnej ilości danych w projekcie albo zespół developerski składa się z kilku programistów, prawdopodobnie nie potrzebujesz wdrażać u siebie tak złożonych rozwiązań.
Bardzo dobrym podejściem może być zaczynanie od architektury monolitycznej. W miarę rozwoju systemu wydzielenie niektórych części systemu wyniknie naturalnie i raczej wydzielimy je słusznie i w odpowiedni sposób. Zaczynając nowy projekt, nie jesteśmy pewni, czy wydzielanie niektórych usług jest konieczne. Mikroserwisy w tym momencie mogą okazać się nie najlepszym wyborem. Aby zapewnić dobrą organizację kodu w monolicie i ułatwić późniejsze wydzielanie odrębnych usług, warto skorzystać z architektury heksagonalnej.
Przejście na architekturę mikroserwisową w istniejącej aplikacji również należy dokładnie przemyśleć. Istnieje szereg usprawnień, które powinniśmy rozważyć przed wdrożeniem tak skomplikowanej architektury.
Podsumowując, jeśli budujesz rozwiązanie dla małej firmy, start-upu lub system nie będzie ogromy, to raczej mikroserwisy nie będą dobrym rozwiązaniem. Dobrze zaplanowany modularny monolit na początek to bardzo trafny wybór.

Ważne, aby w pierwszej kolejności dokładnie przeanalizować wymagania, biorąc pod rozważanie wiele czynników. Gdy w grę wchodzą pieniądze klienta, należy dobrze przemyśleć wszystkie aspekty, aby zaproponować rozwiązanie idealnie dopasowane do budżetu i potrzeb. Na etapie projektowania warto skorzystać ze świeżego spojrzenia architektów z innych zespołów, to pozwala na zaprojektowanie systemu w taki sposób, aby nie tylko był dobry tu i teraz, ale również służył klientowi w przyszłości z uwzględnieniem minimalnych kosztów.
Każdy z nas uwielbia nowe i ciekawe technologie, ale wynik analizy nie zawsze mówi, że to, co jest trendy, jest odpowiednim rozwiązaniem w danym przypadku. Jeśli nie chcemy być zespołem przytłoczonym przez wielką i ciężką machinę mikroserwisów, to warto na początek rozważyć inne lżejsze rozwiązania.
Jeśli artykuł Ci się podobał, zapraszam do polubienia profilu na facebooku oraz obserwowania na instagramie. Zapraszam również do grupy Wsparcie w programowaniu i do kontaku.